How to Write a Compiler #4 - The Parser
The Parser takes a stream of tokens, checks the syntax is valid and produces an Abstract Syntax Tree.
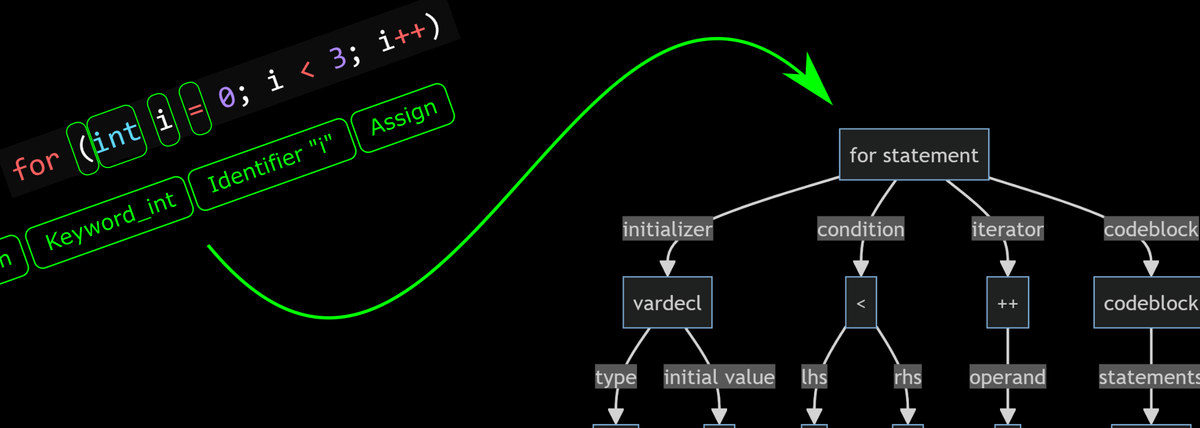
The Parser
Now that we've got a Tokenizer and an Abstract Syntax Tree we've got everything we need to build the Parser.
The parser's job is to read the tokens from the tokenizer, check they conform to the syntax rules of the language and produce a fully populated abstract syntax tree.
Just like the AST, this falls into two main categories - statements and expressions.
Parsing Statements
Parsing statements is a relatively straight forward process:
- If the current token is a flow control statement
if,for,whileetc... then call a dedicated function to parse the supported syntax of each statement type. - If the current token is an open brace
{then the statement is a code block, and the parser just recursively parses its contents into anAstCodeBlockstatement. - Otherwise, the statement must be an expression or declaration statement - call a dedicated function for this.
Here's the code from C-minor that does this:
AstStatement ParseStatement()
{
// Flow control statements
switch (_tokenizer.Token)
{
case Token.Keyword_break:
return ParseBreakStatement();
case Token.Keyword_continue:
return ParseContinueStatement();
case Token.Keyword_for:
return ParseForStatement();
case Token.Keyword_if:
return ParseIfStatement();
case Token.Keyword_return:
return ParseReturnStatement();
case Token.Keyword_switch:
return ParseSwitchStatement();
case Token.Keyword_do:
return ParseDoWhileStatement();
case Token.Keyword_while:
return ParseWhileStatement();
case Token.Keyword_throw:
return ParseThrowStatement();
case Token.Keyword_try:
return ParseTryStatement();
}
// Braced statement block?
if (_tokenizer.Token == Token.OpenBrace)
{
return ParseCodeBlock();
}
// Function declaration, variable declaration or expression statement
return ParseExpressionOrDeclarationStatement(0);
}
Flow Control Statements
Flow control statements are parsed by following the required and optional parts of the statement and building the associated AST element.
Here's an example for the if statement:
AstIfStatement ParseIfStatement()
{
// Create 'if' Statement
var stmt = new AstIfStatement(_tokenizer.TokenPosition);
// Skip "if"
_tokenizer.Next();
// Parse the condition expression
// '(' <condition> ')'
_tokenizer.SkipToken(Token.OpenRound);
stmt.Condition = ParseExpression();
_tokenizer.SkipToken(Token.CloseRound);
// Parse the true block
stmt.TrueBlock = ParseCodeBlock();
// If there's an else block parse it too
if (_tokenizer.TrySkipToken(Token.Keyword_else))
stmt.FalseBlock = ParseCodeBlock();
// Done
return stmt;
}
That's the entire code for parsing an if statement. The other flow control statements are all very similar.
The parsing code makes extensive use of helper functions provided by the tokenizer:
SkipToken- checks the current token matches a particular token and if so moves to the next token. Otherwise, it throws aCodeExceptionreporting a syntax error.TrySkipToken- checks if the current token matches a particular token and if so moves to the next token and return true. Otherwise, it returns false.- There are other similar functions for skipping identifiers and various unexpected token helpers.
Note that at this point we've enforced the syntax of the if statement but haven't checked the statement is correct. eg: we haven't checked the condition expression evaluates to a boolean value.
Similarly, we haven't checked for statements that are only supported in certain contexts. For example, a continue statement can only be used inside a loop but the parser doesn't care and will happily include it anywhere in the AST.
Code Blocks
A code block is a sequence of one or more statements, optionally enclosed in braces. Here's how they're parsed:
AstCodeBlock ParseCodeBlock()
{
// Create a code block statement
var block = new AstCodeBlock(_tokenizer.TokenPosition);
// Is it a braced code block?
if (_tokenizer.TrySkipToken(Token.OpenBrace))
{
// Yes, parse statements until the close brace
block.WasBraced = true;
while (!_tokenizer.TrySkipToken(Token.CloseBrace))
{
block.Statements.Add(ParseStatement());
}
}
else
{
// Not braced, parse just a single statement
block.Statements.Add(ParseStatement());
}
return block;
}
Notice how braces are handled to group a block of statements as a single statement. This allows the same parsing code to be used for cases where braces are required vs optional. Eg:
- The true/false blocks of an
ifstatement can be either a single statement or a braced block of statements.ParseCodeBlockhandles either case. - The code blocks of a
try/catchstatement are always braced. To enforce this the code that parsestrystatements just checks for an open brace before callingParseCodeBlock.
Although not strictly necessary for the abstract syntax tree, the code block remembers if the block was originally braced or not. This is only used for reformatting the AST to text for debugging purposes and isn't used otherwise.
Parsing Declarations
Declarations are probably the trickiest part of the parser because we can't always tell whether it's a declaration or an expression until we get some way into things.
Declarations include:
- variables eg:
int x; - functions eg:
void fn() { } - type declarations eg:
class MyClass { }
The approach here is to:
- Capture the current position in the tokenizer.
- Try to parse a declaration - if it succeeds, then use it and continue on.
- Otherwise, rewind the tokenizer to the saved position and try again as an expression.
AstStatement ParseExpressionOrDeclarationStatement(ParseFlags flags)
{
// Function or variable declaration
var decl = TryParseDeclaration(flags);
if (decl != null)
return decl;
// Must be an expression statement
var pos = _tokenizer.TokenPosition.Start;
var expr = ParseExpression();
if (!flags.HasFlag(ParseFlags.NoConsumeSemicolon))
_tokenizer.SkipToken(Token.SemiColon);
return new AstExpressionStatement(pos)
{
Expression = expr
};
}
(the NoConsumeSemicolon flag is used when parsing the initializer of a for statement).
Parsing Expressions
Finally, we come to parsing expression nodes. The main thing to get right here is the order-of-operation which is established by having the parser functions for lower order of operations call parse functions for higher order operations.
Let's take a look at the function for parsing the add and subtract binary operator. Add and subtract have equal order of operation, are evaluated left to right and have lower order of operation than multiply and divide.
// Parse add/subtract expression nodes
AstExprNode ParseAddSub()
{
// Parse the LHS
var lhs = ParseMulDiv();
// Parse RHS while it's a add or subtract
while (true)
{
switch (_tokenizer.Token)
{
case Token.Plus:
{
// Create binary add operator
var binOp = new AstExprNodeBinaryOp(_tokenizer.TokenPosition);
_tokenizer.Next();
binOp.LHS = lhs;
binOp.RHS = ParseMulDiv();
binOp.Operator = BinaryOperatorType.Add;
// Binary op becomes the new LHS
lhs = binOp;
break;
}
case Token.Minus:
{
// Create binary subtract operator
var binOp = new AstExprNodeBinaryOp(_tokenizer.TokenPosition);
_tokenizer.Next();
binOp.LHS = lhs;
binOp.RHS = ParseMulDiv();
binOp.Operator = BinaryOperatorType.Subtract;
// Binary op becomes the new LHS
lhs = binOp;
break;
}
default:
// Not an add or subtract, finish.
return lhs;
}
}
}
Consider this expression:
a * b + c * dand imagine the tokenizer is currently on the a identifier token and we've just entered the ParseAddSub method:
- The
ParseMulDivfunction is called. This will consume thea * band return an binary expression node to multiplyaandb - The
ParseAddSubfunction then sees theToken.Plustoken and creates a newAstExprNodeBinaryOpfor addition. - It sets the left-hand side to the previously parsed result from ParseMulDiv.
- It then parses another mul/div expression and sets it as the right-hand side.
- The new expression node is then set as the left-hand side and the whole operation is repeated for as long as there's an add or subtract token.
What we end up with is an expression tree that looks like this:
flowchart TD
add[+] --> mul
add[+] --> mul2
mul[*] --> a
mul[*] --> b
mul2[*] --> c
mul2[*] --> dYou might be wondering how parentheses work? Let's look at this expression:
a * (b + c) * dThe ParseMulDiv function is basically an exact copy of the ParseAddSub function except it calls an even higher order of operation parser for its operands. At the very top of the order of operation the parser looks for round parentheses and recurses back into itself.
AstExprNode ParsePrimaryRoot()
{
switch (_tokenizer.Token)
{
/* OTHER CASES OMITTED */
// Grouped expression `(` <subexpression> `)`
case Token.OpenRound:
{
// Skip '('
_tokenizer.Next();
// Parse the sub-expression
node = ParseExpression();
// Must end with a ')'
_tokenizer.SkipToken(Token.CloseRound);
return node;
}
// ...
So when ParseMulDiv parses its right-hand operand after parsing the a operand, it will get back a binary node adding b + c and the expression tree looks like this:
flowchart TD
mul[*] --> a
mul[*] --> add
add[+] --> b
add[+] --> c
mul2[*] --> mul[*]
mul2[*] --> dIt's the order that these expression parsing functions call each other that establishes order of operation.
Here's the full set of expression parsing functions from highest to lowest order of operation (ie: each function calls the one above it to parse its operands).
// literals, identifiers, '(' ')'
AstExprNode ParsePrimaryRoot()
// function call `()`, member accessor `.`, postfix `++` and `--`
AstExprNode ParsePrimarySuffix()
// (type cast)
AstExprNode ParsePrimary()
// prefix `++` and `--`, negate `-`, unary plus `+`,
// logical not `!`, one's complement `~`
AstExprNode ParseUnary()
// `*`, `/` and `%`
AstExprNode ParseMulDiv()
// `+` and `-`
AstExprNode ParseAddSub()
// `<<` and `>>`
AstExprNode ParseShift()
// `<`, `<=`, `>` and `>=`
AstExprNode ParseRelational()
// `==` and `!=`
AstExprNode ParseEquality()
// `&`
AstExprNode ParseBitwiseAnd()
// `^`
AstExprNode ParseBitwiseXor()
// `|`
AstExprNode ParseBitwiseOr()
// `&&`
AstExprNode ParseLogicalAnd()
// `||`
AstExprNode ParseLogicalOr()
// `? :` (conditional operator)
AstExprNode ParseTernary()
// Entry point to parsing an expression
AstExprNode ParseExpression()
Parser API
That's most of the internal workings of the Parser but you might be wondering where it all starts? What kicks it off?
The API to the Parser is essentially just one function ParseCompilationUnit - see here.
A compilation unit represents an entire source code file.
/// <summary>
/// Parses a "compilation unit" (aka a source code file)
/// </summary>
/// <param name="source">The <see cref="CodeFile"/> to parse</param>
/// <returns>The AST of the entire file</returns>
public AstCompilationUnit ParseCompilationUnit(CodeFile source)
{
// Create tokenizer
_tokenizer = new Tokenizer(source);
// Create compilation unit ast
var unit = new AstCompilationUnit(_tokenizer.TokenPosition);
// Parse all statements
unit.Statements = ParseStatements();
// Check nothing unexpected at the end of the file
_tokenizer.CheckToken(Token.EOF);
return unit;
}
Here's everything needed to parse a file:
try
{
// Load code
var codefile = CodeFile.FromFile("my-cminor-program.cm");
// Parse it
var parser = new Parser();
var ast = parser.ParseCompilationUnit(codefile);
// Work with ast...
}
catch (CodeException x)
{
// Syntax error
Console.WriteLine(x.Message);
}
(Note the parser has no internal state so the one instance can be re-used to parse multiple files).
Syntax Checked!
The Tokenizer and Parser have now been brought together to produce an Abstract Syntax Tree. At this point we have the entire structure of the program loaded and we know it's syntactically correct.
We're now ready to start working with the AST. To do that we'll be making extensive use of the visitor design pattern and in the next post I'll be showing how it's implemented and used with C-minor's AST.