How to Write a Compiler #3 - Abstract Syntax Trees
Ask anyone who's worked on a compiler, and they'll all agree that the Abstract Syntax Tree is the most important structure in the whole compiler. But what exactly is it and what is it used for?
What is an Abstract Syntax Tree?
An Abstract Syntax Tree (aka AST) is a tree graph of elements that represent the entire input program.
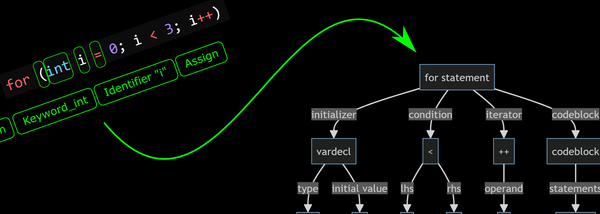
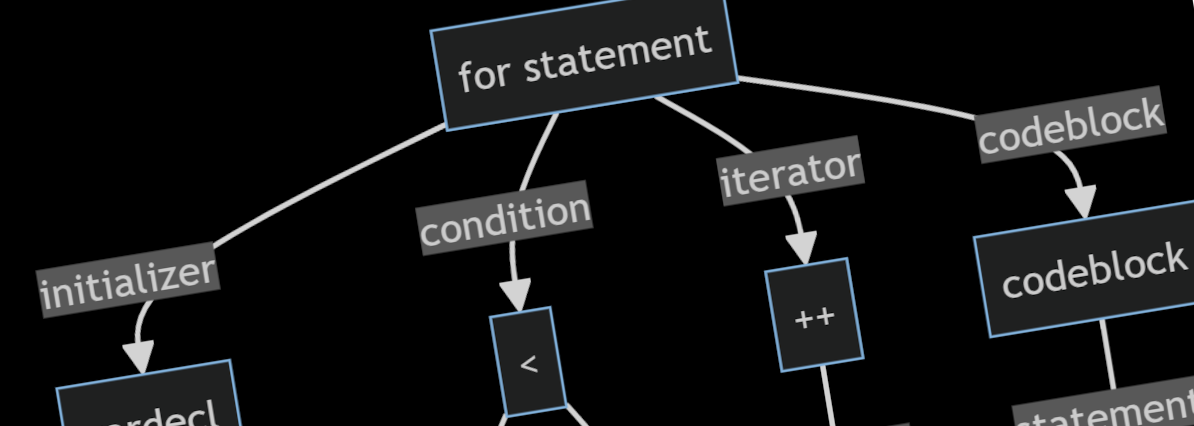
The easiest way to understand it is with a simple example. Consider this if statement:
if (x < y)
{
print("less");
}
else
{
return 0;
}The abstract syntax tree for this statement would look something like this:
flowchart TD
if[if statement]
cond[<]
x[x]
y[y]
if --condition--> cond
cond --> x
cond --> y
if --trueblock--> true
true[codeblock] --statements--> meth1
if --falseblock--> false
false[codeblock] --statements--> retstmt
meth1[method call]
meth1--LHS-->id1
meth1--parameters-->p1
p1[expr literal 'less']
id1[identifier 'print']
retstmt[return] --value--> retval
retval[expr literal 0]This AST can be read as follows:
- An
ifstatement with three connected elements- a condition expression
- a code block of statements to execute if the condition is true
- a code block of statements to execute if the condition is false
- The
conditionis a less than comparison<operator with two operandsxandy - The
true blockis a method call, on the identifierprintwith a single parameter - a literal string "less" - The
false blockis a return statement with the literal value0
Statements vs Expression Nodes
Everything in the AST falls under one of two main categories:
- Statements - control flow statements and declaration (functions, variables, types etc...).
- Expression Nodes - anything that has a value (literals, function calls, operator results etc...)
In C-minor these two categories are represented by the base classes AstStatement and AstExprNode - both of which derived from a common base class AstElement.
classDiagram
class AstElement{
+CodePosition Position
}
AstElement <|-- AstStatement
AstElement <|-- AstExprNode
AstStatement <|-- all_statements
AstExprNode <|-- all_exprnodes
class all_statements["all statement types"]
class all_exprnodes["all expression nodes types"]
From AstStatement and AstExprNode there are derived classes for all the different element types - you can see the full list here.
(note that even though these classes are in a Topten.Cminor.Ast ok namespace I've kept the "Ast" prefix because their names tend to become a bit generic without it).
Declarations are Statements
As far as C-minor is concerned declarations (functions, variables, classes etc...) are also statements even though not technically statements if you take that word to mean something that executes.
Expression Statements
Although statements and expressions are generally different things, there's a special statement for expressions that are statements.
Consider a statement like this:
print("Hello World");This is an expression, but it's used as a statement. The AstExpressionStatement class is used to represent this.
Order of Operation
It's worth noting that order of operation is implicit in the AST and doesn't need to record grouping tokens like parentheses.
Consider these two expressions:
# expression A
x + y * z
# expression B
(x + y) * zExpression A is represented as:
flowchart TD
add --> x
add --> multiply
multiply --> y
multiply --> zExpression B is represented as:
flowchart TD
add --> x
add --> y
multiply --> add
multiply --> zThe grouping parentheses in the original expression B is used by the parser to construct the correct tree and then discarded.
Syntactic Structure, Little Meaning
The AST stores the syntactic structure of the input program but by itself ascribes very little meaning to its elements.
For example:
- identifiers are recorded as identifier nodes but say nothing about whether the identifier represents a local variable, parameter, method or function, a class name etc...
- the AST allows function and class declarations anywhere statements are allowed so there's nothing to stop the declaration of a class inside a function (even though this is not supported in C-minor)
- the AST will happily record operations on incompatible arguments (eg: string + integer) or passing an incorrect number of arguments to a function.
In other words, at this stage all we're doing is capturing the syntactic structure of the program and meaning will be applied and correctness checked later as part of "semantic analysis".
Position Information
Just like every token produced by the tokenizer has a CodePosition describing where it came from, every element in the AST also has a position. In later stages as we're performing checks on the AST and we find problems we've got the position readily available to report the original location of the error.
Time to Parse!
The AST is a tree of elements that describe a program's syntactic structure but not its meaning.
Each node is either a statement or an expression. Order of operation is implicit in the arrangement of nodes that make an expression. Every node in the AST has position information attached for error reporting.
The AST is central to everything else the compiler does - it'll be used for building the type system, semantic analysis, code generation and more.
Now that we have a way to represent the AST the next challenge is to build a correctly formed AST from a stream of tokens... and that's the job of the parser.